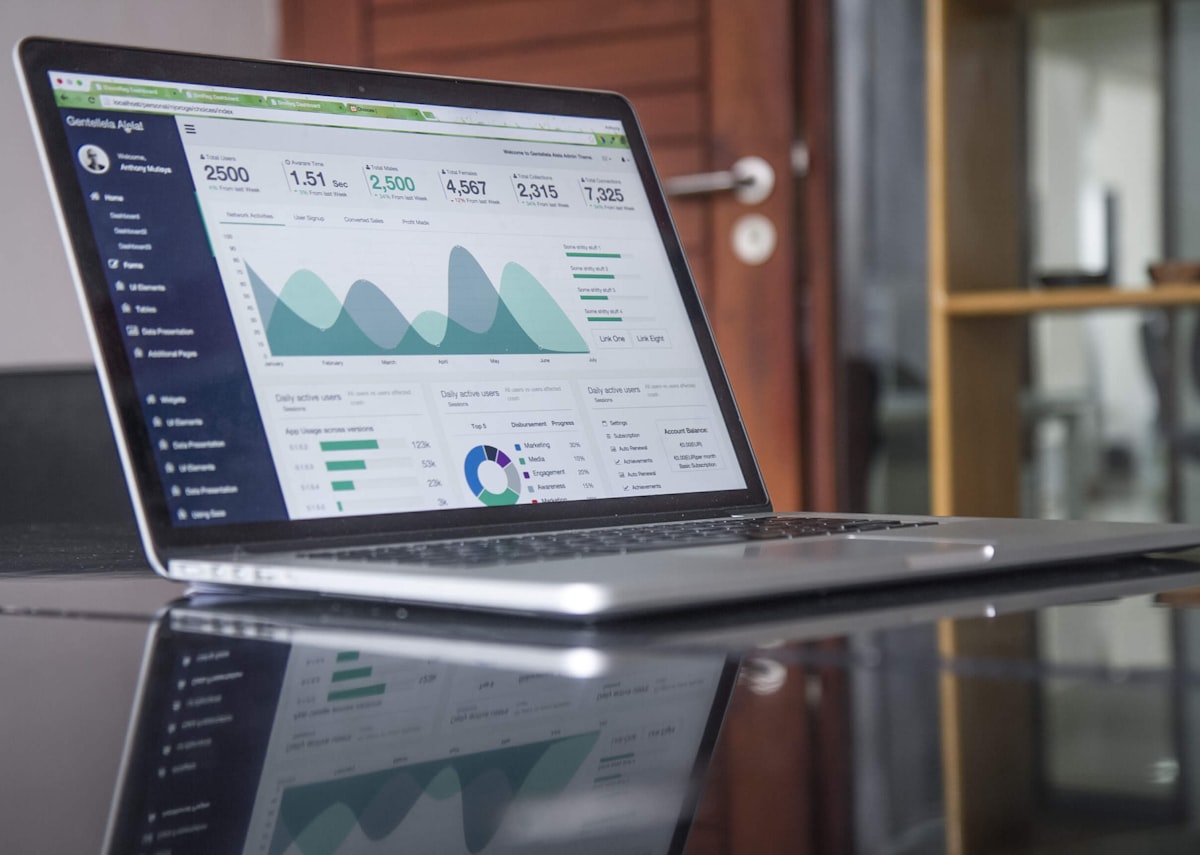
Two years ago, Coderbuds was a code review tool. You connected your GitHub or BitBucket repo, and we'd score every pull request on a 10-100 scale. Activity, quality, size, complexity — distilled into a number that told you whether your team was shipping clean code or shipping chaos.
That was the entire product. And at the time, it felt like plenty.
Today, 12 autonomous AI agents run across your engineering team's workflows. They chase stale reviews. They coach developers who ship 2,000-line PRs. They detect knowledge silos. They redistribute workload. They monitor deployment health. They nudge, coach, escalate, and close — without a human touching a dashboard.
Nobody planned this arc. It happened because the ground kept shifting.
#The Score That Stopped Being Enough
When we launched PR scoring, the thesis was simple: if you measure code quality consistently, teams improve. And they did. Scores went up. PRs got smaller. Reviews got more thoughtful.
But engineering leaders kept asking the same question: "Great, my PR scores improved. Is my team actually better?"
Fair question. A team can have pristine PRs and still take three weeks to ship a feature. A developer can write beautiful code and still be burning out. A high score on every review doesn't tell you whether you're deploying to production once a quarter or ten times a day.
The score measured the artifact. It didn't measure the system.
#Adding DORA Felt Like the Answer. It Wasn't.
So we added DORA metrics. Deployment frequency. Lead time. Change failure rate. Mean time to recovery. The four metrics that Google's research team spent years proving correlate with high-performing teams.
DORA gave engineering leaders something they'd never had: an objective, benchmarkable view of their delivery pipeline. You could finally say "we deploy daily with a 5% failure rate" and know that puts you in the top tier.
For about six months, DORA felt like the answer. Then the cracks showed.
We watched a team hit Elite status across all four metrics while three of their senior engineers quietly updated their LinkedIn profiles. Another team had phenomenal deployment frequency because one person was doing 80% of the work. A third team's lead time looked incredible because they'd stopped doing meaningful code reviews entirely.
DORA measures the machine. It says nothing about the people running it.
#The SPACE Framework: Measuring What Matters and What Hurts
The turning point was adopting Microsoft's SPACE framework — Satisfaction, Performance, Activity, Communication, Efficiency. Built by the same researcher who created DORA, it was designed to capture what output metrics miss: whether the pace is sustainable, whether collaboration is healthy, whether developers actually enjoy their work.
We added developer satisfaction surveys. We started tracking collaboration patterns — who reviews whose code, how workload distributes, where knowledge concentrates. We built cycle time breakdowns that showed not just how long features take, but where the time goes.
Suddenly, we could see the full picture. The team with elite DORA scores and failing morale. The developer carrying twice the review load. The repo where one person is the only reviewer and nobody's noticed the bus factor.
But seeing the picture and fixing it are very different things.
#The Insight That Changed Everything
Here's what we learned building an engineering intelligence platform: leaders don't lack data. They lack time.
An engineering manager sees 147 data points across their dashboard. They know reviews are slow. They know one developer is overloaded. They know a PR has been open for three weeks. They know the team isn't using AI tools effectively.
They also have a roadmap to deliver, stakeholders to manage, one-on-ones to run, and a hiring pipeline that's been open for four months. The problems are visible. The bandwidth to fix them isn't.
So we built an AI insights engine. Instead of showing a dashboard full of numbers and hoping someone notices the pattern, we surfaced the pattern directly: "Your review cycle time increased 40% this sprint because @sarah has been the sole reviewer on 12 of 15 PRs."
Better. But still not enough. Because now the engineering lead reads the insight, nods, and adds it to a mental list of things to address when they have a spare moment. Which is never.
#From Insights to Agents: The Logical Conclusion Nobody Expected
The shift from insights to agents happened because we asked a question that feels obvious in retrospect: if we can identify the problem and we know the fix, why are we waiting for a human to execute it?
The Review Chaser agent doesn't show you a graph of review wait times. It DMs the reviewer after four hours, escalates at eight, and comments on the PR at twenty-four. The problem is identified and addressed in the same motion.
The PR Size Coach doesn't flag a metric in a dashboard. It messages the author directly: "This PR is 1,847 lines. Here's how to split it into three focused changes." Then it follows up next week if the pattern continues.
The Workload Balancer doesn't generate a report showing uneven distribution. It notices @mike is carrying twice the team average and redistributes four reviews before anyone opens a spreadsheet.
Twelve agents, mapped to the SPACE framework, each handling a specific class of problem that engineering leaders have always known about but never had the bandwidth to address consistently.
This is the part that caught us off-guard. We didn't set out to build an AI agents platform. We set out to help teams do better code reviews. But every time we solved one layer of the problem, the next layer revealed itself. Measure quality. Measure delivery. Measure sustainability. Surface patterns. Act on patterns. Automate the action.
The product evolved because the job evolved. And it's still evolving.
#What This Tells You About Engineering Leadership in 2027
Here's the projection, and it's not subtle: the role of engineering manager is being unbundled.
Not eliminated. Unbundled.
Today, an engineering manager does a dozen different jobs. They're a process enforcer ("keep PRs small"), a load balancer ("someone else needs to review this"), a performance tracker ("our lead time is slipping"), a culture builder ("let's recognize great work"), a talent scout ("who needs to grow"), and a strategy translator ("here's why this quarter matters").
Half of those jobs are pattern recognition plus consistent action. An agent can chase a stale review more reliably than a human who also has seven Slack threads open and a 2pm with the VP of Product. An agent can redistribute workload without the social awkwardness of telling someone they're not pulling their weight.
The half that remains — setting direction, making judgment calls, building trust, navigating ambiguity — becomes the entire job. The management overhead gets automated. The leadership doesn't.
This is the same shift happening to individual contributors, just at a different altitude. Engineers are becoming agent operators. Managers are becoming agent orchestrators. The common thread: the repetitive, pattern-based work gets absorbed by systems. The judgment, context, and human connection become the scarce resource.
#The Metrics Problem Nobody's Solved Yet
Here's the uncomfortable truth that the industry is dancing around: our measurement systems were designed for a world that's disappearing.
Pull requests made sense when a human wrote every line. Velocity made sense when there was a roughly linear relationship between effort and output. DORA made sense when the delivery pipeline was the primary bottleneck.
When agents generate code, chase reviews, balance workload, and coach developers, what exactly are you measuring? The agent's throughput? The human's judgment calls? The team's ability to configure agents well?
GitHub's former CEO just raised $60m to build Entire from scratch because the existing system — issues, PRs, deployments — was never designed for this. The plumbing is changing and nobody has the new blueprints yet.
We're in the awkward middle. DORA still matters, but it's losing signal. SPACE captures more dimensions, but agents are changing the shape of each dimension. Activity means something different when half the activity is agent-initiated. Collaboration means something different when an agent is redistributing reviews.
The teams that figure out measurement for this new world will have a structural advantage. Not because metrics are magic, but because you can't improve what you can't see. And right now, most teams are flying instruments designed for a different aircraft.
#What Actually Changes
Let me be concrete about what an engineering team looks like when this plays out:
The standup disappears. Not because someone read a blog post about async work. Because agents surface blockers in real time. A stale PR gets nudged before anyone mentions it in a morning call. A deployment failure gets flagged and attributed before the team assembles.
The manager's week restructures around judgment, not administration. Instead of spending Monday reviewing metrics dashboards, Tuesday chasing review bottlenecks, and Wednesday reallocating work — all of that runs continuously. The manager's time goes to architecture decisions, career development conversations, and the messy strategic problems that agents can't parse.
The 1:1 changes. Instead of "how's your workload?" (the agent already knows), it becomes "where do you want to grow?" and "what's the hardest problem you're stuck on?" The rote check-in becomes a genuine coaching conversation because the data layer is handled.
Team size economics shift. If agents handle the coordination overhead that scales with team size, the optimal team gets smaller. Not because people are replaced, but because the tax of managing humans working together drops. A five-person team with agents does what a twelve-person team does without them. Not because they code faster. Because they waste less.
#The Part Nobody Wants to Talk About
The hardest thing about this transition isn't technical. It's identity.
For engineering managers, being the person who "knows what's happening" across the team is a core part of the job. When agents have better real-time awareness than any human could, that knowledge advantage evaporates. The manager who built their reputation on always knowing the status of every PR now competes with a system that literally monitors every PR.
For individual contributors, the identity shift is even deeper. Writing code isn't just a job description for most of us. It's a craft we spent decades building, a source of pride rooted in scarcity. "I can solve this problem that most people can't." When an agent can solve the same problem in seven minutes, the scarcity moves. It doesn't disappear — it just migrates from execution to judgment.
The ones who make the shift become something more valuable. Virtuoso to conductor. Hearing the whole symphony, knowing when something's off, even if they're not the ones playing every instrument. Scarcity of skill replaced by scarcity of judgment.
And judgment, it turns out, is worth more.
#Where We're Going
We started by scoring pull requests. Now our agents run the daily operating rhythm of engineering teams.
The next layer is already visible. Agents that don't just react to patterns but anticipate them. Agents that learn your team's specific rhythms — that this developer goes dark before a vacation and that one ships large PRs on Fridays. Agents that propose process changes based on outcomes, not just enforce existing rules.
The engineering team of 2028 won't look like an engineering team at all by today's standards. It'll look like a small group of people with exceptional judgment, surrounded by systems that handle everything pattern-based, measured by frameworks that don't exist yet, producing output at a scale that makes current benchmarks meaningless.
We'll keep building toward that. Not because we planned it from the start — we didn't. But because every time we solve one layer, the next one reveals itself.
The ground is still shifting. Best to keep moving.
#Related Reading
- AI Agents in Software Development: What Engineering Leaders Need to Know - The broader industry landscape
- SPACE Framework vs DORA Metrics: Which Should You Use? - Choosing the right measurement approach
- Measuring AI Coding Tool ROI: A Practical Framework - Quantifying the impact
- Engineering Metrics Maturity Model - Where your team sits in the journey
Coderbuds gives engineering teams full observability, SPACE framework metrics, and 12 autonomous AI agents that make high performance the default. Every action tracked. Every result proven. Enable your first agent in 5 minutes.